Dieses Projekt beschäftigt sich mit der Frage, wie Musik mit Hilfe von künstlicher Intelligenz visualisiert werden kann. Dabei sollen nicht nur Musikmerkmale einen Einfluss auf die finale Visualisierung nehmen. Es soll auch möglich sein, Emotionen und Gefühle, die durch die Musik beim Hörer ausgelöst werden, durch manuell annotierte Musik in der Visualisierung widerzuspiegeln.
Zur Generierung der Visualisierung wird das generative künstliche Netzwerk “StyleGAN” verwendet, das basierend auf einem trainierten Bilder-Trainingsset neue, der Verteilung des Trainingssets entsprechende künstliche Bilder generieren kann (StyleGAN2 PyTorch GitHub Repository). Da die genutzte Version von StyleGAN in PyTorch implementiert wird, wird außerdem PyTorch als Deep Learning Framework für Python verwendet. Für die Visualisierung kann jedes beliebige, vortrainierte StyleGAN Netzwerk verwendet werden. Für dieses Projekt wurde ein Netzwerk verwendet, das gemalte Kunstwerke generieren kann.
Zur Extraktion von Merkmalen bzw. Features aus Musik wird die Python Bibliothek “librosa” verwendet. Einerseits wird in diesem Projekt aus der Musik ein Chromagram extrahiert, dass die vorkommenden Töne oder Noten aus der Musik in eine metrische Repräsentation umwandelt. Andererseits werden sogenannte Onsets aus der Musik extrahiert, die die Intensitäten plötzlicher Energieänderungen in der Musik darstellen und somit den “Percussion”-Anteil, wie Schlaginstrumente, der Musik in eine metrische Repräsentation bringen. Beide diese Musikmerkmale können anschließend einen Einfluss auf den Eingabevektor für den StyleGAN Generator ausüben, aus dem das künstlich generierte Bild entsteht. Auf diese Weise lösen die beiden genannten Merkmale Veränderungen in den generierten Bildern aus, die die Harmonik und den Rhythmus der Musik widerspiegeln. Auf den folgenden beiden Bildern sind beide beschriebenen Features abgebildet.
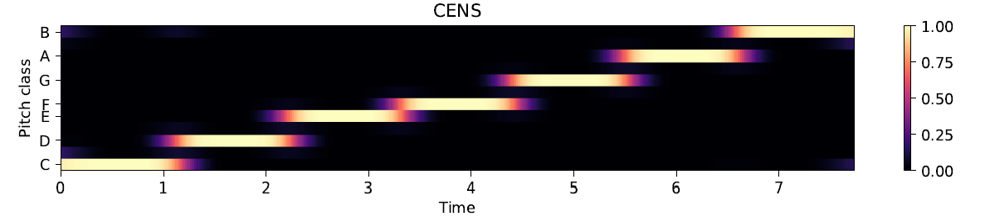
Chromagram einer Tonleiter C-Dur
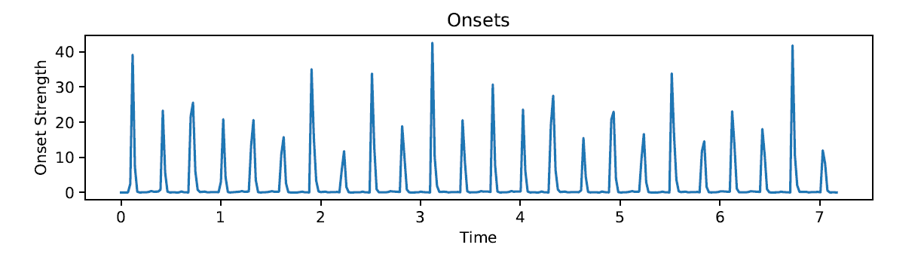
Onsets Beispiel eines Drumbeats
Eine Eigenschaft von StyleGAN ist es, dass die generierten Bilder von einem zufälligen Eingabevektor abhängig sind. Daher ist es nicht möglich, bestimmte Merkmale oder den Inhalt eines generierten Bildes zu bestimmen. Da in diesem Projekt jedoch manuelle Annotationen einen Einfluss auf die generierte Bilder nehmen sollen, wurde eine Kombination von CLIP und StyleGAN, StyleCLIP, verwendet. Durch CLIP ist es möglich, einen Text und ein Bild durch zwei Encoder zu enkodieren, um so die Ähnlichkeit zwischen dem Inhalt des Textes und dem Inhalt des Bildes zu ermitteln. Die Ähnlichkeit wird benutzt, um in der nächsten Iteration ein StyleGAN Bild zu generieren, in dem die Ähnlichkeit zu dem eingegeben Text vergrößert wird. Durch diese Kombination ist es möglich, den Inhalt von StyleGAN Bildern besser zu kontrollieren. In folgender Abbildung ist eine solche StyleCLIP Suche mit der eingegebenen Annotation “A painting of a calm place” zu sehen. Durch diese Annotation kann beispielsweise eine ruhige, entspannende Melodie unterstützt werden. Mit Hilfe der Verwendung von StyleCLIP ist es möglich, semantisch definierte Bilder, anstelle von komplett zufälligen, für die Visualisierung zu generieren.

StyleCLIP Suche, Annotation: “A painting of a calm place”
Nachdem durch StyleCLIP passende StyleGAN Bilder mit ihren zugehörigen Eingabevektoren gefunden wurden, werden diese mit den vorgestellten Musikfeatures kombiniert, woraus anschließend durch StyleGAN die kompletten Einzelbilder der Visualisierung generiert werden können.
Konkret wurden in diesem Projekt folgende Schritte erarbeitet:
- StyleGAN zur Generierung von künstliche Bildern
- Extraktion von Musikmerkmalen (Chromagram und Onsets) und deren Interaktion mit StyleGAN
- Interpolationen in StyleGAN, um eine flüssige Visualisierung zu ermöglichen
- StyleCLIP, um den Inhalt der Visualisierung durch Annotationen/Semantik unterstützen zu können
- Kombination der genannten Komponenten zur Generierung einer kompletten Visualisierung
Beispiel Ergebnis
Im Folgenden ist ein beispielhaftes Ergebnis einer Visualisierung zu sehen. Die Audiospur für die Visualisierung ist aus zwei verschiedenen Musikstücken zusammengeschnitten und beinhaltet zu jedem der Musikstücke eine eigene Annotation. In der Visualisierung findet zwischen den verschiedenen Musikabschnitten ein weicher Übergang statt:
Source Code
Der Source Code für das Projekt ist in GitLab verfügbar: https://gitlab.iue.fh-kiel.de/robert.manzke/ai-music-visuals